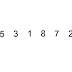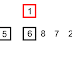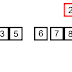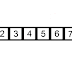In computer science, a binary search or half-interval search algorithm finds the position of a specified value (the input "key") within a sorted array. At each stage, the algorithm compares the input key value with the key value of the middle element of the array. If the keys match, then a matching element has been found so its index, or position, is returned. Otherwise, if the sought key is less than the middle element's key, then the algorithm repeats its action on the sub-array to the left of the middle element or, if the input key is greater, on the sub-array to the right. If the remaining array to be searched is reduced to zero, then the key cannot be found in the array and a special "Not found" indication is returned.
A binary search halves the number of items to check with each iteration, so locating the an item (or determining its absence) takes logarithmic time. A binary search is a dichotomic divide and conquer search algorithm.
Searching a sorted collection is a common task. A dictionary is a sorted list of word definitions. Given a word, one can find its definition. A telephone book is a sorted list of people's names, addresses, and telephone numbers. Knowing someone's name allows one to quickly find their telephone number and address.
If the list to be searched contains more than a few items (a dozen, say) a binary search will require far fewer comparisons than a linear search, but it imposes the requirement that the list be sorted. Similarly, a hash search can be faster than a binary search but imposes still greater requirements. If the contents of the array are modified between searches, maintaining these requirements may take more time than the searches! And if it is known that some items will be searched for much more often than others, and it can be arranged that these items are at the start of the list, then a linear search may be the best.
Program for Binary Search #include<stdio.h>
#include<iostream.h>
#include<iomanip.h>
#include<conio.h>
int bsearch(int a[],int low,int high,int ele);
void main()
{
int a[10],i,n,ele,found=0;
clrscr();
cout<<"enter the no of elements in to array";
cin>>n;
cout<<"enter elements in sorted order";
for (i=0;i<n;i++)
{
cin>>a[i];
}
cout<<"enter the element to be searched";
cin>>ele;
cout.setf(ios::fixed|ios::left);
cout<<setw(10)<<"LOW"<<setw(10)<<"MID"<<setw(10)<<"HIGH";
cout<<endl;
found=bsearch(a,0,n-1,ele);
if(found==-1)
cout<<"element not found";
else
cout<<"element found at location "<<found;
getch();
}
int bsearch(int a[],int low, int high, int ele)
{
if(low<=high)
{
int mid =(low+high)/2;
cout<<setw(10)<<low;
cout<<setw(10)<<mid;
cout<<setw(10)<<high;
cout<<endl;
if(ele==a[mid])
return mid;
else if(ele<a[mid])
high=mid-1;
else if(ele>a[mid])
low=mid+1;
bsearch(a,low,high,ele);
}
else
return -1;
}
![\begin{cases}
n & \mbox{if } k = 0 \\[5pt]
\displaystyle\frac{n + 1}{k + 1} & \mbox{if } 1 \le k \le n.
\end{cases}](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_ux3mpoPg5n3PMxX27YKB4iZAVEERRXX-cx9D6aScw810OWuckNI6TngtxB-ppFo78k4nCC33PcctucbIB6qUo5PW_WtCyg_6I1mOd7f04dlWmqGcVNHVyoQ_OZ9vOQIR-Kgq8FZD2Wu3_OFWCj=s0-d)
 . However, if it is known that it occurs once, then at most n - 1 comparisons are needed, and the expected number of comparisons is
. However, if it is known that it occurs once, then at most n - 1 comparisons are needed, and the expected number of comparisons is